News
Guangdong BAIDU Special Cement Building Materials Co.,Ltd— 新闻中心 —
火了!高中生用Minecraft做AI基准,用户看图投票抉
偶尔发明了一个很风趣的 AI 基准测试,点开链接,居然是一个 MineCraft 作品投票页面?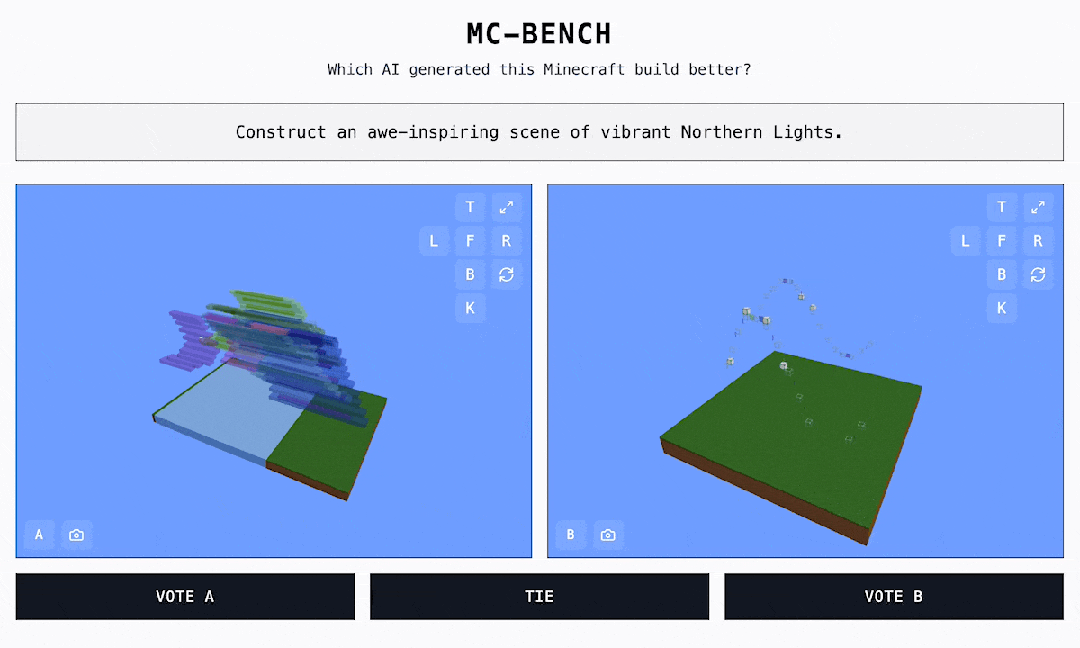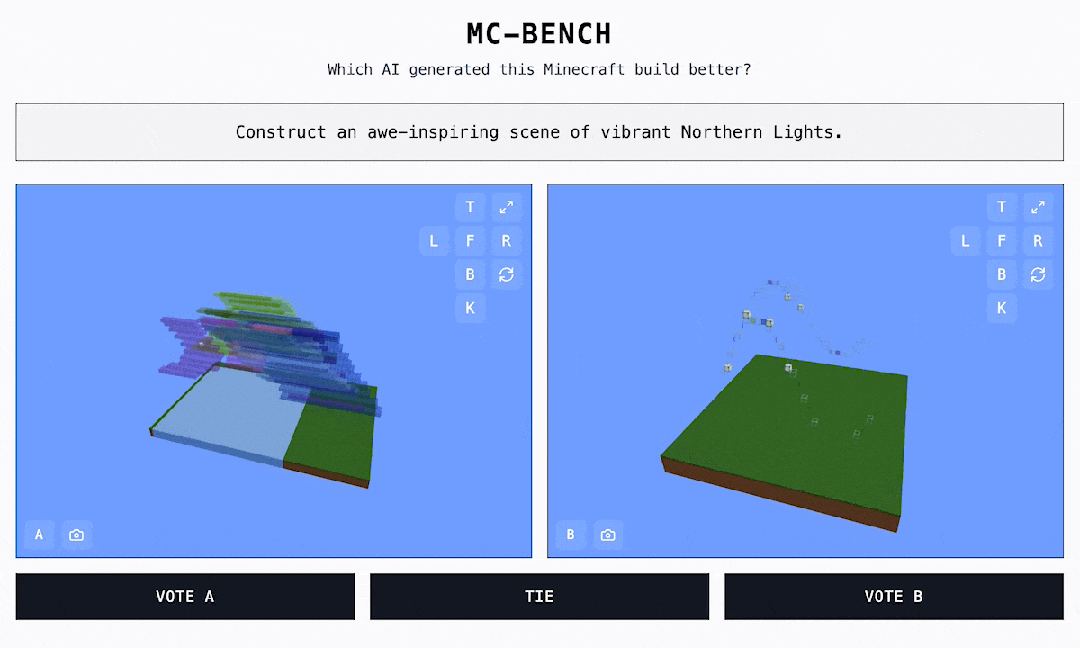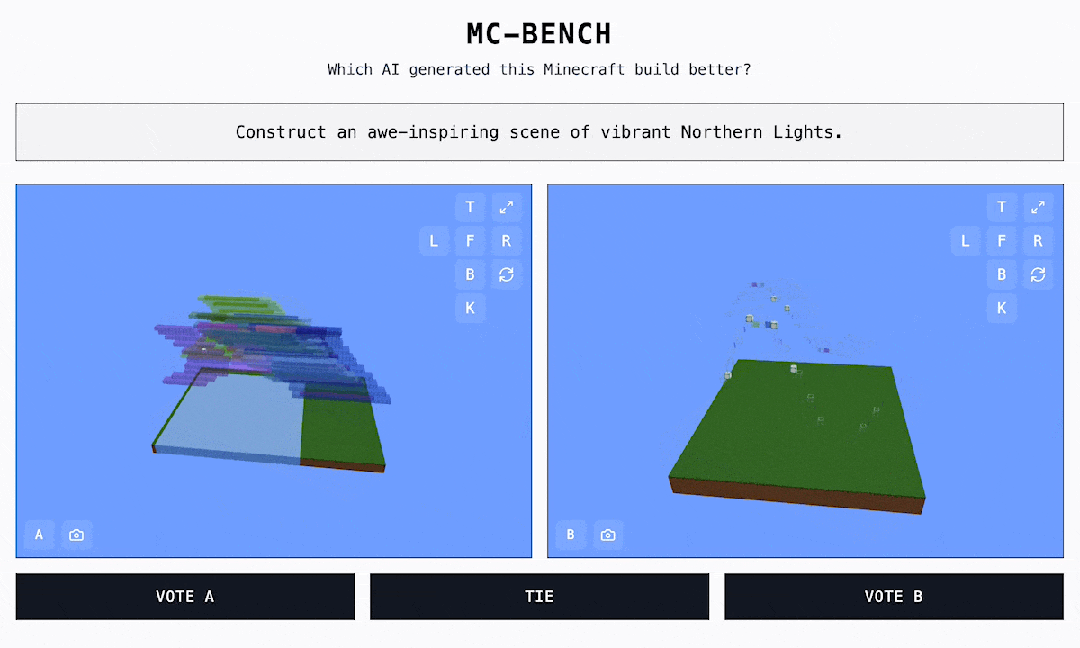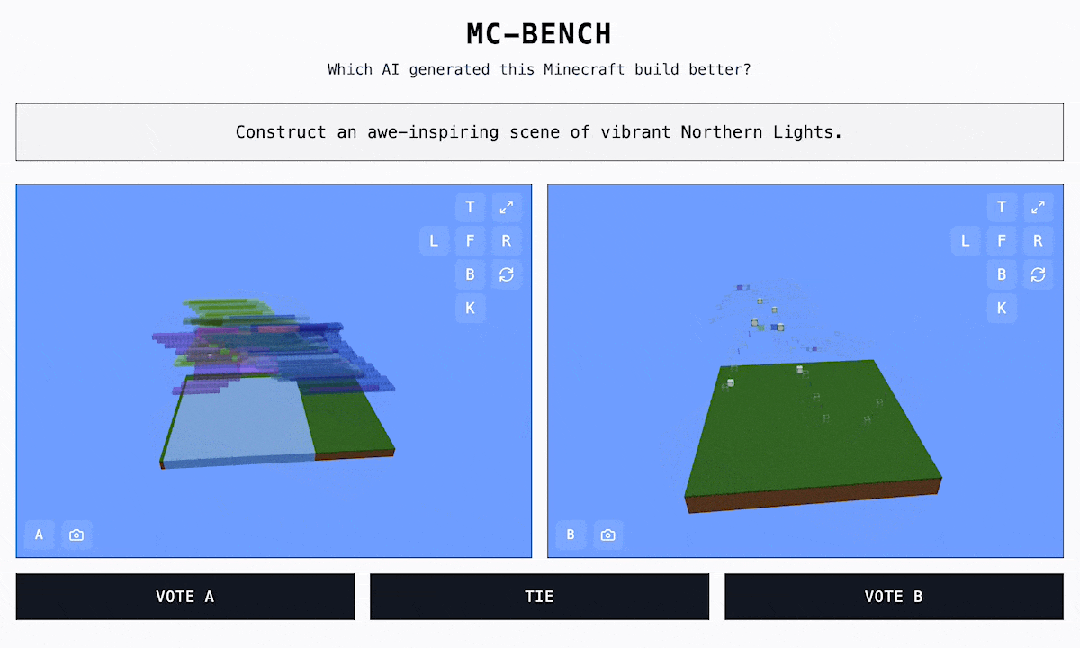 如图所示,这些作品都是 AI 实现的,灰色框中的笔墨对应的是提醒词。黑框是可点击的选项 ——A、B 或许持平。网站地点:https://mcbench.ai/来都来了,先投个票吧。投票之前,作品都是「匿名」的。只有在投票后,咱们才干看到每个 Minecraft 作品是由哪个模子实现的。
如图所示,这些作品都是 AI 实现的,灰色框中的笔墨对应的是提醒词。黑框是可点击的选项 ——A、B 或许持平。网站地点:https://mcbench.ai/来都来了,先投个票吧。投票之前,作品都是「匿名」的。只有在投票后,咱们才干看到每个 Minecraft 作品是由哪个模子实现的。
 在这个基准里,重要看三个维度:指令遵守、代码实现度跟发明力。AI 技巧飞速演进的时期,传统的人工智能基准测试显然不敷用了。总有人能想出一些新鲜的测试方式,比方的沙盒制作游戏 Minecraft。这就是咱们刚看到的 Minecraft Benchmark(MC-Bench)。作为用户,咱们可能参加的局部就是:投票。累计票数中的 ELO 分数决议了每个模子的排名。风趣的是,无论采皇冠赌场官方网站取哪种指标,排行榜的收敛水平都很高:Claude 3.7 3.5 跟 GPT-4.5 都是断层当先。
在这个基准里,重要看三个维度:指令遵守、代码实现度跟发明力。AI 技巧飞速演进的时期,传统的人工智能基准测试显然不敷用了。总有人能想出一些新鲜的测试方式,比方的沙盒制作游戏 Minecraft。这就是咱们刚看到的 Minecraft Benchmark(MC-Bench)。作为用户,咱们可能参加的局部就是:投票。累计票数中的 ELO 分数决议了每个模子的排名。风趣的是,无论采皇冠赌场官方网站取哪种指标,排行榜的收敛水平都很高:Claude 3.7 3.5 跟 GPT-4.5 都是断层当先。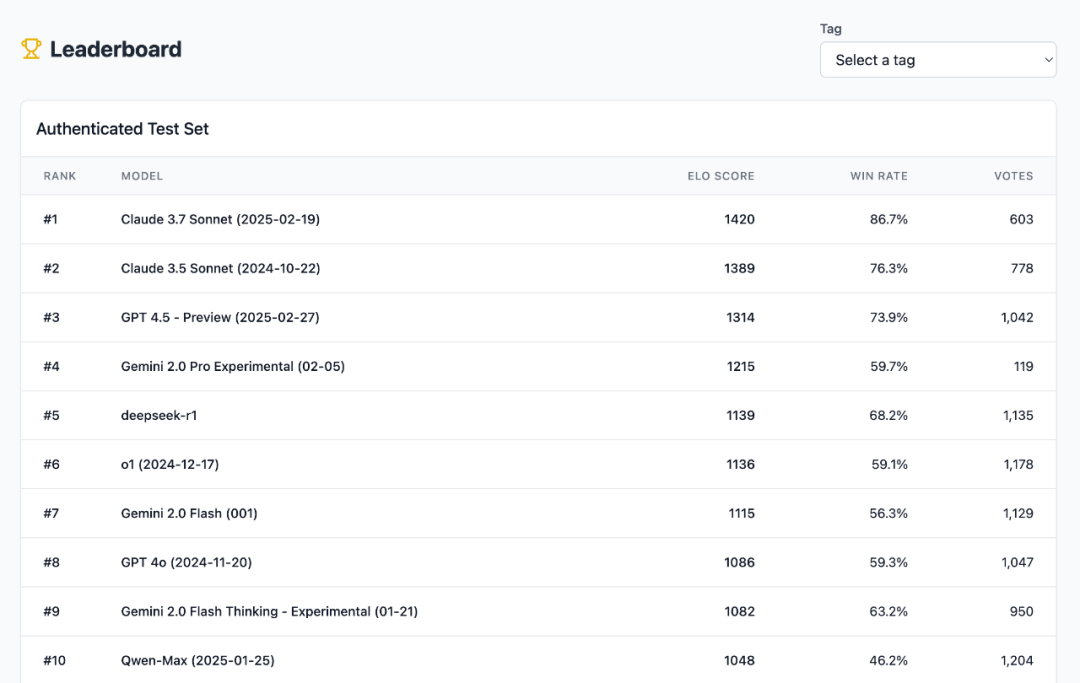 从技巧上讲,MC-Bench 是一个编程基准,由于模子须要编写代码来创立所提醒的构建,如「冰霜雪人」(Frosty the Snowman)或「原始沙岸上诱人的寒带海滨小屋」(a charming tropical beach hut on a ppg电子娱乐十大平台ristine sandy shore)。
从技巧上讲,MC-Bench 是一个编程基准,由于模子须要编写代码来创立所提醒的构建,如「冰霜雪人」(Frosty the Snowman)或「原始沙岸上诱人的寒带海滨小屋」(a charming tropical beach hut on a ppg电子娱乐十大平台ristine sandy shore)。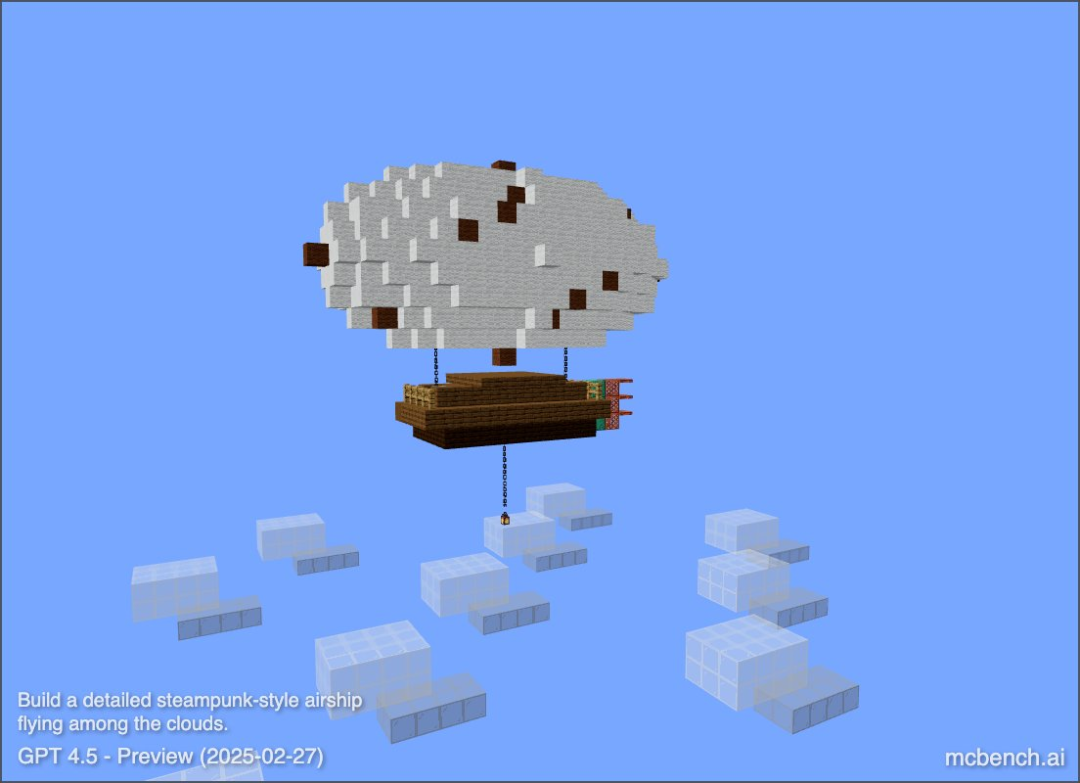 Prompt: build a detailed steampunk-style airship flying among the clouds (一艘在云层中飞翔的具体蒸汽朋克作风飞艇)开办 MC-Bench 的 Adi Singh 是个高中生,在他看来,用 Minecraft 做测试基准的代价并不在于游戏自身,而在于「人们对它的熟习水平」,究竟它是有史以来最滞销的视频游戏。对年夜少数 MC-Bench 用户来说,评估雪人能否更难看要比研讨代码更轻易,这使得该名目存在更普遍的吸引力,从而有可能网络更少数据,以懂得哪些模子的得分一直更高。退一万步说,即便是不玩过这款游戏的人,也能够评价出哪个菠萝的块状表示情势更好,请参考上面这个例子:
Prompt: build a detailed steampunk-style airship flying among the clouds (一艘在云层中飞翔的具体蒸汽朋克作风飞艇)开办 MC-Bench 的 Adi Singh 是个高中生,在他看来,用 Minecraft 做测试基准的代价并不在于游戏自身,而在于「人们对它的熟习水平」,究竟它是有史以来最滞销的视频游戏。对年夜少数 MC-Bench 用户来说,评估雪人能否更难看要比研讨代码更轻易,这使得该名目存在更普遍的吸引力,从而有可能网络更少数据,以懂得哪些模子的得分一直更高。退一万步说,即便是不玩过这款游戏的人,也能够评价出哪个菠萝的块状表示情势更好,请参考上面这个例子: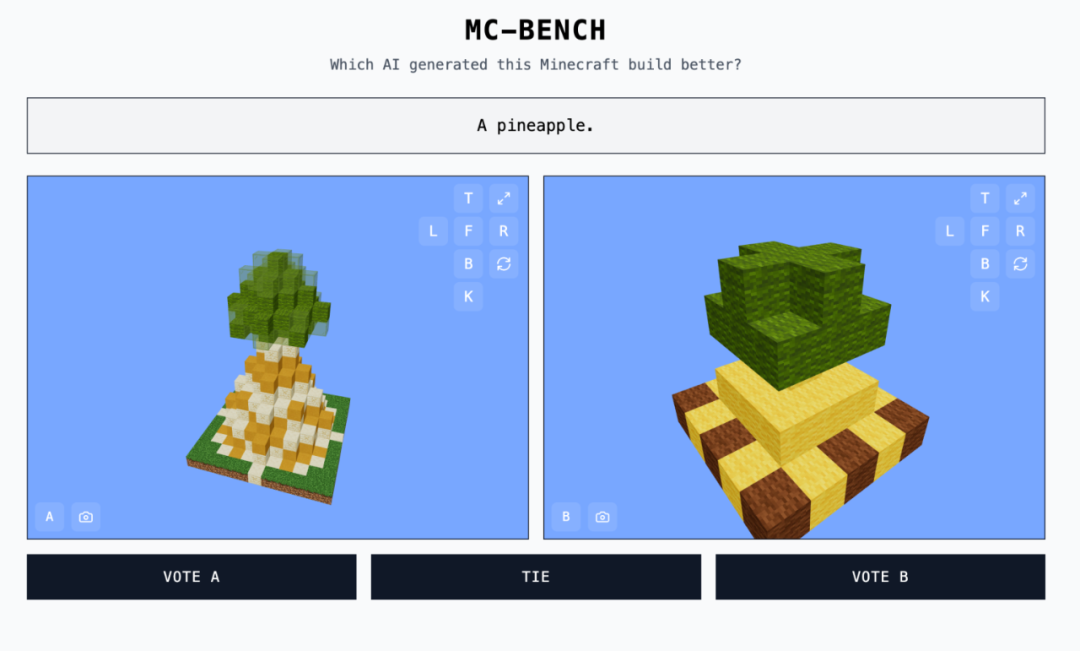 「现在,咱们只是在停止简略的构建,以思考咱们自 GPT-3 时期以来曾经走了多远,但(咱pg娱乐电子游戏官方版们)能够看到本人正在扩大到这些较长情势的打算跟目的导向型义务。游戏可能只是一种测试智能体推理的前言,它比事实生涯中更保险,测试目标也更可控,因而在我看来更幻想。」研讨职员常常在尺度化评价中对人工智能模子停止测试,此中良多测试都市给人工智能带来主场上风。因为人工智能模子的练习方法,它们生成就善于处理某些详细的成绩,尤其是须要逝世记硬背或基本推理的成绩。简略地说,OpenAI 的 GPT-4 能够在 LSAT 测验中获得第 88 百分位数的成就,但却无奈分辨「Strawberry」一词中有几多个 「R」。Anthropic 的 Claude 3.7 Sonnet 在一项尺度化软件工程基准测试中获得了 62.3% 的正确率,但在玩《口袋魔鬼》时却比年夜少数的五岁孩子还差。以是一些开放式的游戏反而能「另辟门路」,供给测验 AI 机能的新鲜视角。在此之前,曾经有良多著名游戏被参加 AI 基准测试的名单,比方《口袋魔鬼》(Pokémon Red)、《陌头霸王》(Street Fighter)跟《猜字游戏》(Pictionary)。
「现在,咱们只是在停止简略的构建,以思考咱们自 GPT-3 时期以来曾经走了多远,但(咱pg娱乐电子游戏官方版们)能够看到本人正在扩大到这些较长情势的打算跟目的导向型义务。游戏可能只是一种测试智能体推理的前言,它比事实生涯中更保险,测试目标也更可控,因而在我看来更幻想。」研讨职员常常在尺度化评价中对人工智能模子停止测试,此中良多测试都市给人工智能带来主场上风。因为人工智能模子的练习方法,它们生成就善于处理某些详细的成绩,尤其是须要逝世记硬背或基本推理的成绩。简略地说,OpenAI 的 GPT-4 能够在 LSAT 测验中获得第 88 百分位数的成就,但却无奈分辨「Strawberry」一词中有几多个 「R」。Anthropic 的 Claude 3.7 Sonnet 在一项尺度化软件工程基准测试中获得了 62.3% 的正确率,但在玩《口袋魔鬼》时却比年夜少数的五岁孩子还差。以是一些开放式的游戏反而能「另辟门路」,供给测验 AI 机能的新鲜视角。在此之前,曾经有良多著名游戏被参加 AI 基准测试的名单,比方《口袋魔鬼》(Pokémon Red)、《陌头霸王》(Street Fighter)跟《猜字游戏》(Pictionary)。 - 上一篇:杨国福麻辣烫又被曝老鼠 间隔前次没有足一个月
- 下一篇:没有了